Este é o primeiro post de uma nova série sobre meta-análises de pacotes R. Com o pacote miniCRAN é possível baixar logs de downloads de pacotes de R por meio do espelho (mirror) do RStudio do CRAN. Cada linha nesses logs representa um download de um pacote por um usuário.
O objetivo desta série é analisar os dados gerados por esses logs.
Para este primeiro post, é mostrado:
- Como baixar os logs de downloads de pacotes do CRAN do RStudio de forma automatizada com o pacote miniCRAN;
- Como selecionar os pacotes R mais populares pelo Princípio de Pareto;
- Os 20 pacotes mais populares;
- Um grafo de redes criado a partir dos pacotes mais populares filtrados e suas dependências.
Os pacotes usados neste post são:
suppressMessages(library(dplyr)) # Usado para agregar os dados em pacotes
suppressMessages(library(igraph)) # Usado para plotar o grafo criado pelo miniCRAN
library(miniCRAN)
library(installr)
library(ggplot2)
library(ggthemes)
library(scales)
library(feather) # Usado para carregar arquivosAs linhas abaixo mostram como eu baixei os logs da mirror do RStudio do CRAN para o período entre 24 de Abril de 2016 a 24 de Maio a 2016. Os logs de cada dia desse período são salvos na pasta indicada no argumento log_folder, totalizando cerca de 250 MB. O dataframe gerado com o código gerado é enorme, por isso é recomendável removê-lo da memória após realizar os filtros desejados a partir dele.
temp_dir <- download_RStudio_CRAN_data(START = '2016-04-24',END = '2016-05-24', log_folder="/home/sillas/R/data")
df_cran <- read_RStudio_CRAN_data("/home/sillas/R/data")
write_feather(df_cran, "/home/sillas/R/data/df_cran.feather")
#save(df_cran, file = "/home/sillas/R/data/df_cran.Rdata")
#load("/home/sillas/R/data/df_cran.Rdata")
# Agregar logs por pacote:
# df_pkgs <- df_cran %>%
# group_by(package) %>%
# summarise(downloads = n()) %>%
# arrange(desc(downloads)) %>%
# mutate(downloads_acum = cumsum(downloads))
#rm(df_cran)df_pkgs <- df_cran %>%
group_by(package) %>%
summarise(downloads = n()) %>%
arrange(desc(downloads)) %>%
mutate(downloads_acum = cumsum(downloads))
write_feather(df_pkgs, "/home/sillas/R/data/df_pkgs.feather")Para não ter de carregar o objeto df_cran toda vez que eu renderizo o arquivo markdown deste post, salvei uma cópia em disco do dataframe df_pkgs. Para isso, usei o pacote feather, que torna os processos de escrita e leitura de arquivos no R muito rápidas.
df_pkgs <- read_feather("/home/sillas/R/data/df_pkgs.feather")
head(df_pkgs, 10)## # A tibble: 10 x 3
## package downloads downloads_acum
## <chr> <int> <int>
## 1 RcppArmadillo 425443 425443
## 2 Rcpp 285869 711312
## 3 ggplot2 246536 957848
## 4 digest 210749 1168597
## 5 stringr 207837 1376434
## 6 plyr 203498 1579932
## 7 stringi 202125 1782057
## 8 magrittr 195198 1977255
## 9 scales 194719 2171974
## 10 reshape2 182363 2354337dim(df_pkgs)## [1] 9236 3Temos que 9236 diferentes pacotes foram baixados no período analisado.
Para determinar a quantidade de pacotes a serem analisados como membros de uma rede, usei o Princípio de Pareto:
(total_downloads <- sum(df_pkgs$downloads))## [1] 17491320(limite80 <- total_downloads * 0.80)## [1] 13993056df_pkgs_pareto <- filter(df_pkgs, downloads_acum <= limite80)
nrow(df_pkgs_pareto)## [1] 335100*nrow(df_pkgs_pareto)/nrow(df_pkgs)## [1] 3.627111Temos que 335 pacotes, cerca de 3,6% do total, equivalem a 80% de todos os downloads de pacotes nos últimos 30 dias, o que mostra que a regra de Pareto é aplicável aqui e que, apesar de haver milhares de pacotes disponíveis no CRAN, a grande maioria deles não são baixados muitas vezes, como mostram as seguintes estatísticas:
summary(df_pkgs$downloads)## Min. 1st Qu. Median Mean 3rd Qu. Max.
## 1 137 182 1894 315 425443O número mediano de downloads por usuário é de 182, muito distante dos 10 mais populares mostrados acima.
Os vinte pacotes mais baixados são:
df_pkgs_pareto %>%
top_n(20, wt = downloads) %>%
ggplot(aes(x = reorder(package, downloads), y = downloads)) +
geom_bar(stat = "identity", fill = "#014d64") +
labs(x = "", y = "Quantidade de downloads\n entre Abril e Maio/2016") +
scale_y_continuous(labels = comma) +
coord_flip() +
theme_economist() 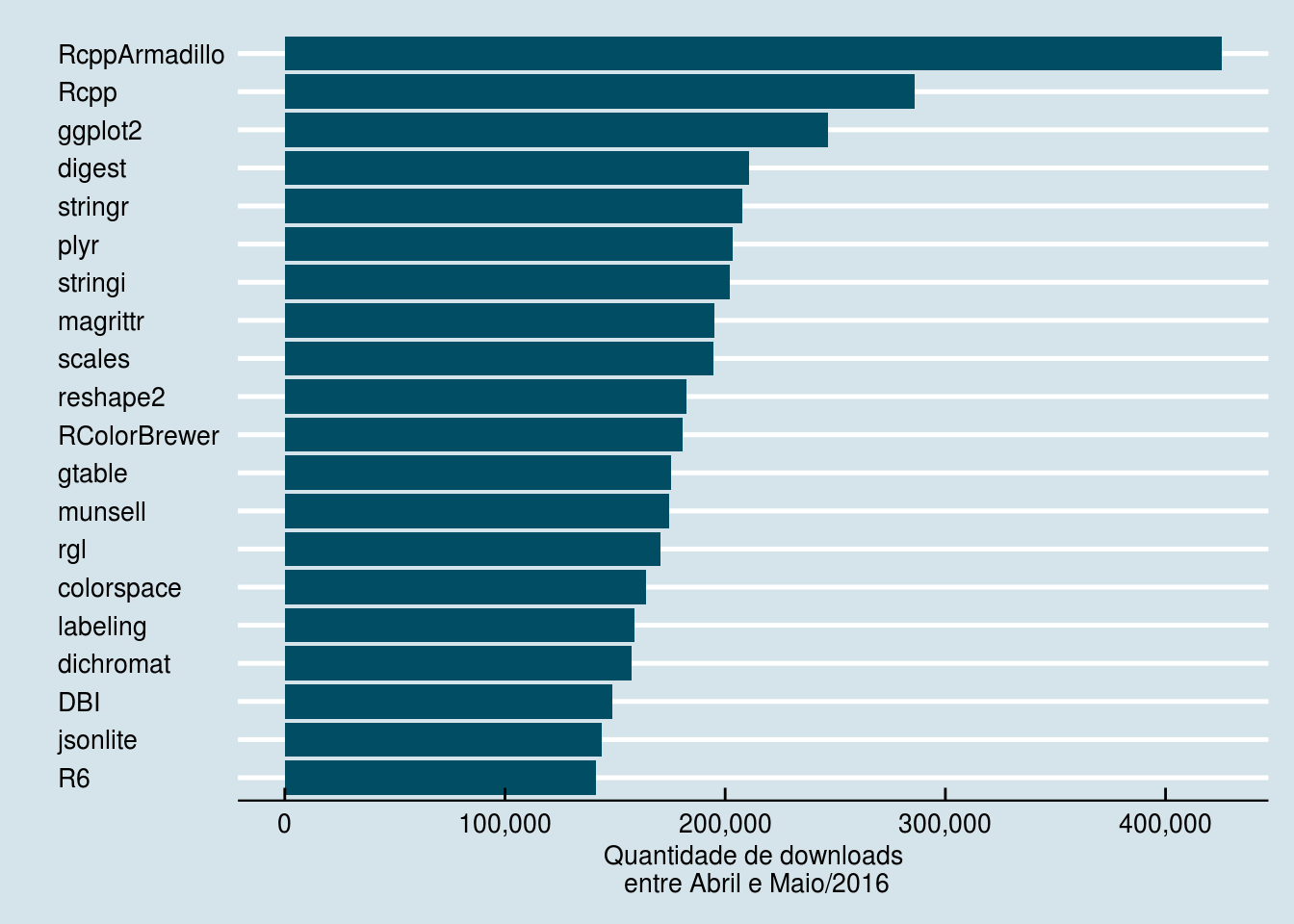
Pessoalmente, não fiquei surpreso ao ver que, dos 6 pacotes mais baixados, 3 (ggplot2, stringr e plyr) fazem parte do Hadleyverse, ou seja, foram criados pelo gênio Hadley Wickham, que revolucionou o modo como o R é usado e é ídolo para muitos usuários da linguagem, como eu :).
Após filtrar os pacotes que entrarão na análise, o pacote miniCRAN é usado para extrair as dependências de cada um e formar uma rede deles. A função makeDepGraph extrai as dependências dos pacotes indicados na função e cria um grafo. Por exemplo:
pkgDep("ggplot2")## [1] "ggplot2" "digest" "gtable" "MASS"
## [5] "plyr" "reshape2" "scales" "tibble"
## [9] "lazyeval" "Rcpp" "stringr" "RColorBrewer"
## [13] "dichromat" "munsell" "labeling" "R6"
## [17] "viridisLite" "rlang" "colorspace" "stringi"
## [21] "magrittr" "jsonlite" "rex" "httr"
## [25] "crayon" "withr" "mime" "curl"
## [29] "openssl" "lattice" "survival" "Formula"
## [33] "latticeExtra" "cluster" "rpart" "nnet"
## [37] "acepack" "foreign" "gridExtra" "data.table"
## [41] "htmlTable" "viridis" "htmltools" "base64enc"
## [45] "knitr" "checkmate" "htmlwidgets" "Matrix"
## [49] "backports" "yaml" "evaluate" "highr"
## [53] "markdown" "maps" "sp" "nlme"
## [57] "mvtnorm" "TH.data" "sandwich" "codetools"
## [61] "zoo" "praise" "SparseM" "MatrixModels"
## [65] "rprojroot" "gdtools" "BH" "covr"
## [69] "ggplot2movies" "hexbin" "Hmisc" "mapproj"
## [73] "maptools" "mgcv" "multcomp" "testthat"
## [77] "quantreg" "rmarkdown" "svglite"makeDepGraph("ggplot2")## IGRAPH 8db7e3d DN-- 79 149 --
## + attr: name (v/c), type (e/c)
## + edges from 8db7e3d (vertex names):
## [1] magrittr ->rex lazyeval ->rex
## [3] jsonlite ->httr mime ->httr
## [5] curl ->httr openssl ->httr
## [7] R6 ->httr lattice ->withr
## [9] lattice ->latticeExtra RColorBrewer->latticeExtra
## [11] gtable ->gridExtra stringr ->htmlTable
## [13] knitr ->htmlTable magrittr ->htmlTable
## [15] checkmate ->htmlTable htmlwidgets ->htmlTable
## + ... omitted several edgesAssim, dos 335 pacotes mais populares, são gerados dois grafos: o da esquerda, com o método plot com as modificações nativas realizadas pelo miniCRAN e o da direita, feita pelo pacote igraph.
set.seed(123)
list_pkgs <- df_pkgs_pareto$package
g <- makeDepGraph(list_pkgs)
par(mfrow=(c(1,2)))
plot(g, vertex.size=10, cex=0.7, main = "") # método plot.pkgDepGraph
plot.igraph(g)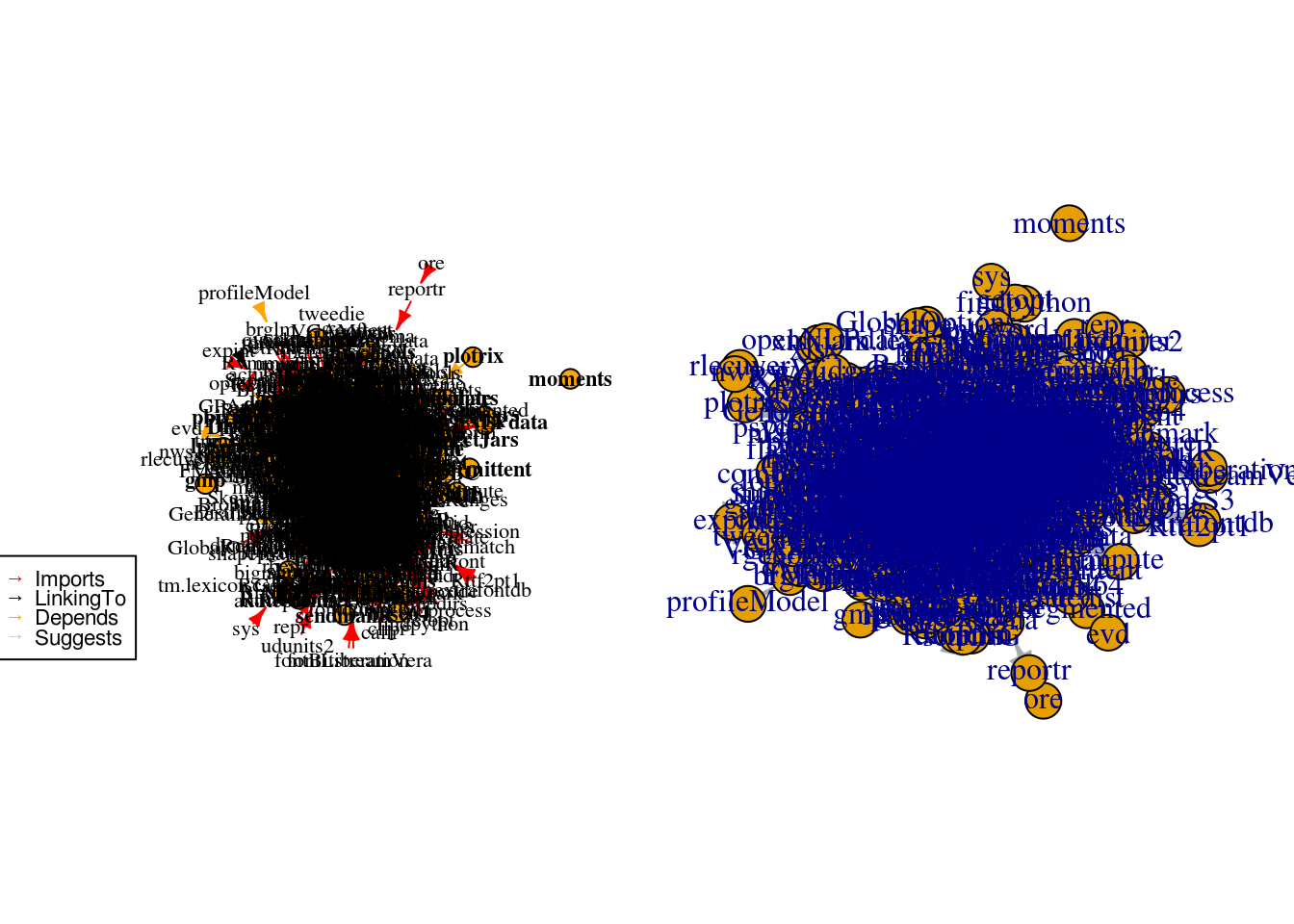
Como pode-se ver, ambos os gráficos acima são visualmente poluídos e não dá para aprender muita coisa a partir deles. Além disso, a fim de analisar a centralidade de um pacote em um grafo, é importante saber o que o argumento suggests da função makeDepGraph significa. Segundo Hadley Wickham, quando o pacote A sugere um outro pacote B, significa que o A pode usar o pacote B, mas ele não é requerido. Este pode ser usado para rodar testes, montar vignettes (tutoriais de pacotes), etc.
Vamos, então, como fica o grafo dos 20 pacotes mais populares, com e sem suggests, com o pacote ggplot2 destacado:
list_pkgs <- df_pkgs$package[1:20]
par(mfrow=(c(1,2)))
g <- makeDepGraph(list_pkgs, enhances = FALSE, suggests = FALSE)
set.seed(123)
plot(g, pkgsToHighlight = "ggplot2",vertex.size=20, cex=1, main = "Argumento suggests = FALSE", legendPosition = NULL)
g <- makeDepGraph(list_pkgs, enhances = FALSE, suggests = TRUE)
set.seed(123)
plot(g, pkgsToHighlight = "ggplot2", vertex.size=20, cex=1, main = "Argumento suggests = TRUE", legendPosition = c(-1, -1))
Agora sim já é possível aprender algumas coisas a partir do grafo. O sentido da linha vermelha indica que, por exemplo, o ggplot2 importa vários pacotes(digest, gtable, MASS, reshape2, plyr e scales), mas não é importado por nenhum outro. Já o grafo da direita mostra que o ggplot2 sugere muitos outros, o que aumenta sua centralidade na rede.
Conclusão: para realizar análises de centralidade de pacotes R, é necessário deixar o argumento suggests como FALSE.