Motivação
Esta matéria da Folha de São Paulo me motivou a fazer algo que sempre tive muito interesse e que foi responsável por ajudar a desenvolver meu raciocínio analítico: baixar um conjunto de dados público, fazer minhas próprias análises e tirar conclusões que considero interessantes.
Ao baixar o dataset neste link, contudo, meu primeiro obstáculo foi o formato em que os dados foram disponbilizados. Problemas como células mescladas, problemas de encoding, formato matricial (e não tidy) de tabelas, etc. Além disso, o próprio nome dos arquivos não esclarece seu conteúdo e não facilita o trabalho de quem deseja juntar as diferentes tabelas para tirar conclusões criativas.
Por exemplo, existe relação entre renda familiar e a “popularidade” de uma zona de destino de viagens? Bairros mais ricos recebem mais trabalhadores da indústria, de serviços ou de comércio? Quais distritos de São Paulo mais “exportam” pessoas que pegam metrô para buscar emprego? As possibilidades de análises e modelagens são muitas.
Com esta motivação, ao perceber que o trabalho de limpeza de dados, realizado neste código, poderia ser trabalhoso para mais gente além de mim, decidi exportar os arquivos no Kaggle em um arquivo SQLite que contem as tabelas, além de salvar as tabelas individualmente em arquivos csv após passar pelo processo de limpeza e padronização de dados.
Como usar os dados
O dplyr tem um recurso muito legal: pode interagir diretamente com arquivos SQL, sejam eles como arquivo local ou como um sistema de banco de dados hospedado em algum servidor. O Rstudio possui um site com vários tutoriais sobre trabalhar com bancos de dados SQL.
library(RSQLite)
library(tidyverse)
# apos baixar o arquivo SQLITE chamado DB_ORIGEM_DESTINO_SP do Kaggle,
# indique abaixo o caminho para o arquivo
arquivo_db <- "/home/sillas/R/Projetos/pesquisa_origem_destino/data/DB_ORIGEM_DESTINO_SP"
# criar conexao com o banco
con <- dbConnect(RSQLite::SQLite(), dbname = arquivo_db)A função dbListTables exibe quais tabelas estão disponíveis:
dbListTables(con)## [1] "dados_geograficos_das_zonas"
## [2] "dados_gerais"
## [3] "dados_gerais_por_zona_de_pesquisa_2017"
## [4] "dicionario_das_variaveis_da_tabela_dados_gerais"
## [5] "dicionarios_de_variaveis_da_tabela_de_dados_gerais_encodificadas"
## [6] "empregos_com_trabalho_externo_ou_interno_por_zona_de_emprego_2017"
## [7] "empregos_em_endereco_fixo_na_propria_residencia_e_sem_endereco_fixo_por_zona_de_emprego_2017"
## [8] "empregos_por_classe_de_atividade_e_zona_de_emprego_2017"
## [9] "empregos_por_setor_de_atividade_e_zona_de_emprego_2017"
## [10] "empregos_por_vinculo_empregaticio_e_zona_de_emprego_2017"
## [11] "familias_por_numero_de_automoveis_particulares_e_zona_de_residencia_2017"
## [12] "matriculas_escolares_por_tipo_de_estabelecimento_e_zona_de_escola_2017"
## [13] "populacao_por_condicao_de_atividade_e_zona_de_residencia_2017"
## [14] "populacao_por_faixa_de_renda_familiar_mensal_e_zona_de_residencia_2017"
## [15] "populacao_por_faixa_etaria_e_zona_de_residencia_2017"
## [16] "populacao_por_genero_e_zona_de_residencia_2017"
## [17] "populacao_por_grau_de_instrucao_e_zona_de_residencia_2017"
## [18] "populacao_que_trabalha_por_vinculo_empregaticio_do_primeiro_trabalho_e_zona_de_residencia_2017"
## [19] "renda_total_renda_media_familiar_renda_per_capita_e_renda_mediana_familiar_por_zona_de_residencia_2017"
## [20] "tempo_medio_das_viagem_produzidas_por_tipo_de_viagem_e_zona_de_origem_2017"
## [21] "viagens_diarias_a_pe_por_zonas_de_origem_e_destino_2017"
## [22] "viagens_diarias_atraidas_por_modo_principal_e_zona_de_destino_2017"
## [23] "viagens_diarias_atraidas_por_motivo_e_zona_de_destino_2017"
## [24] "viagens_diarias_atraidas_por_tipo_e_zona_de_destino_2017"
## [25] "viagens_diarias_motorizadas_por_zonas_de_origem_e_destino_2017"
## [26] "viagens_diarias_nao_motorizadas_por_zonas_de_origem_e_destino_2017"
## [27] "viagens_diarias_por_bicicleta_e_zonas_de_origem_e_destino_2017"
## [28] "viagens_diarias_por_modo_coletivo_e_zonas_de_origem_e_destino_2017"
## [29] "viagens_diarias_por_modo_individual_e_zonas_de_origem_e_destino_2017"
## [30] "viagens_diarias_produzidas_a_pe_por_razao_de_escolha_do_modo_e_zona_de_origem_2017"
## [31] "viagens_diarias_produzidas_por_modo_principal_e_zona_de_origem_2017"
## [32] "viagens_diarias_produzidas_por_motivo_e_zona_de_origem_2017"
## [33] "viagens_diarias_produzidas_por_tipo_e_zona_de_origem_2017"
## [34] "viagens_diarias_totais_por_zonas_de_origem_e_destino_2017"Para iniciantes nesse dataset, as tabelas mais importantes são estas:
dbListTables(con)[c(1, 4, 5)]## [1] "dados_geograficos_das_zonas"
## [2] "dicionario_das_variaveis_da_tabela_dados_gerais"
## [3] "dicionarios_de_variaveis_da_tabela_de_dados_gerais_encodificadas"Para interagir com uma tabela desse banco de dados, usa-se a função tbl():
tbl(con, # arquivo de conexao com o banco
"dicionario_das_variaveis_da_tabela_dados_gerais") # nome da tabela)## # Source: table<dicionario_das_variaveis_da_tabela_dados_gerais> [?? x
## # 2]
## # Database: sqlite 3.22.0
## # [/home/sillas/R/Projetos/pesquisa_origem_destino/data/DB_ORIGEM_DESTINO_SP]
## VAR_NOME VAR_CONTEUDO
## <chr> <chr>
## 1 ZONA Zona do Domicílio
## 2 MUNI_DOM Município de Domicílio
## 3 CO_DOM_X Coordenada X Domicílio
## 4 CO_DOM_Y Coordenada Y Domicílio
## 5 ID_DOM Identifica Domicílio
## 6 F_DOM Identifica Primeiro Registro do Domicílio
## 7 FE_DOM Fator de Expansão do Domicílio
## 8 DOM Número do Domicílio
## 9 CD_ENTRE Código de Entrevista
## 10 DATA Data da Entrevista
## # … with more rowsO dplyr faz, então, algo que se chama de consulta lazy: o output acima não é um dataframe ou tibble, mas sim uma breve exibição das primeiras linhas do resultado da consulta à tabela. O benefício disso é que o resultado da consulta não foi carregado para a memória RAM, o que é muito útil ao lidar com bancos de dados muito grandes e queries complexas.
No código abaixo, por exemplo, eu junto duas tabelas diferentes e filtro as zonas da cidade de São Paulo para só então “baixar” ou trazer os dados para a memória RAM com a função collect():
df_zonas_sp <- tbl(con, "dados_gerais") %>%
left_join(tbl(con, "dados_geograficos_das_zonas"),
by = c("ZONA" = c("COD_ZONA"))) %>%
# filtrar zonas de SP
filter(NOME_MUNICIPIO == "São Paulo") %>%
collect()A partir dos dados obtidos, podemos fazer qualquer tipo de análise desejada. Por exemplo, um gráfico contendo a renda familiar mediana por distrito na cidade de São Paulo:
# distritos por renda familiar
renda_por_distrito <- df_zonas_sp %>%
filter(!is.na(RENDA_FA)) %>%
group_by(NOME_AREA_SP_CAPITAL, NOME_DISTRITO) %>%
summarise(RENDA_MEDIANA = median(RENDA_FA))
quartis <- quantile(renda_por_distrito$RENDA_MEDIANA,
prob = c(.25, .50, .75))
renda_por_distrito %>%
ggplot(aes(x = fct_reorder(NOME_DISTRITO, RENDA_MEDIANA),
y = RENDA_MEDIANA)) +
geom_col(fill = "#A82B2EFE") +
geom_hline(yintercept = quartis, linetype = "dashed") +
facet_wrap(vars(NOME_AREA_SP_CAPITAL), scales = "free_y") +
labs(x = NULL, y = NULL,
title = "Mediana da renda familiar por zona na cidade de SP") +
scale_y_continuous(breaks = seq(0, 10000, 2000),
minor_breaks = NULL) +
coord_flip()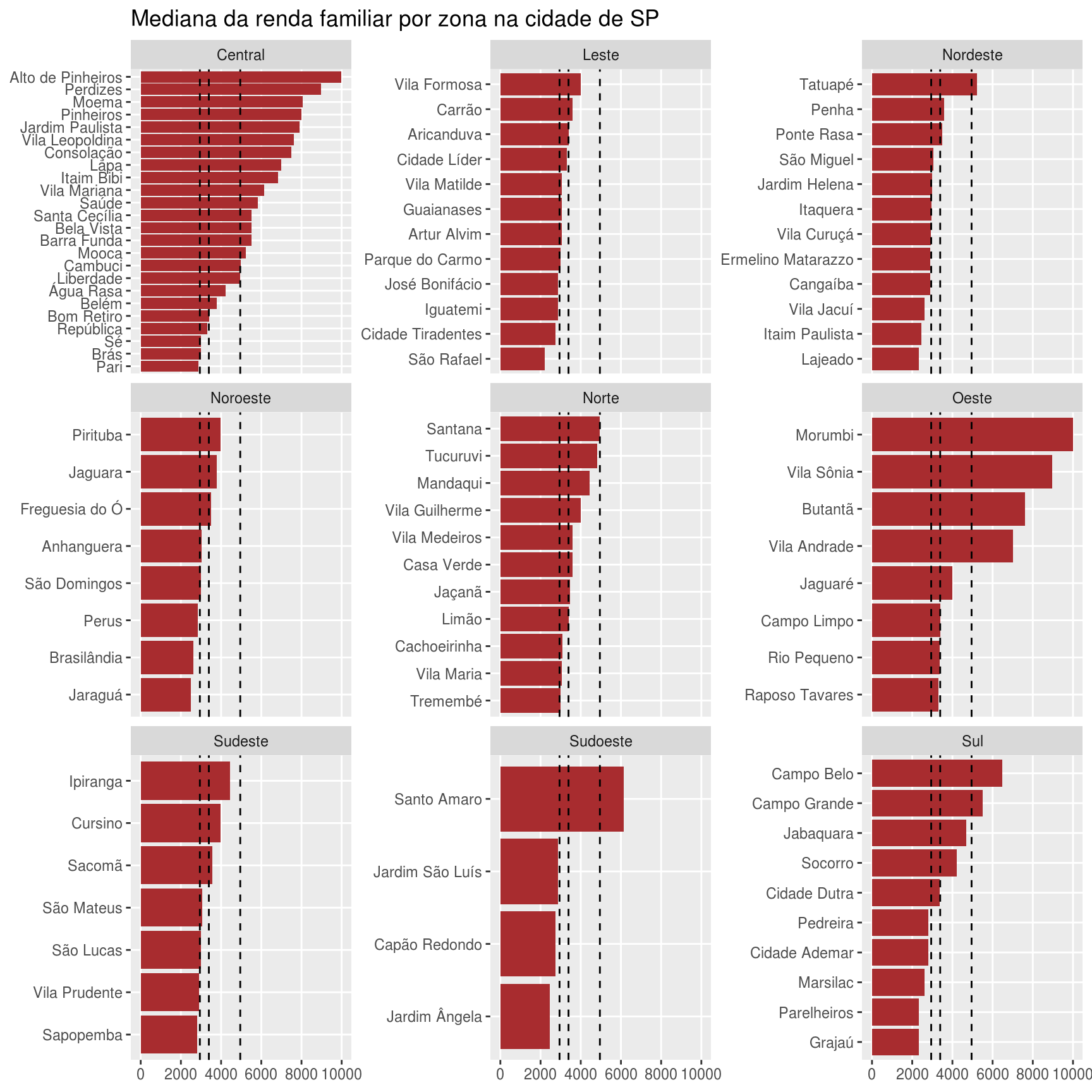
Outro tipo de análise possível pelo cruzamento de tabelas: Para onde vão as pessoas que partem da Luz?
# para onde as pessoas que moram na luz vão?
tb_zona_de_para <- tbl(con, "dados_geograficos_das_zonas") %>%
select(COD_ZONA, NOME_ZONA)
tbl(con, "viagens_diarias_totais_por_zonas_de_origem_e_destino_2017") %>%
left_join(tb_zona_de_para, by = c("COD_ZONA_ORIGEM" = "COD_ZONA")) %>%
rename(NOME_ZONA_ORIGEM = NOME_ZONA) %>%
left_join(tb_zona_de_para, by = c("COD_ZONA_DESTINO" = "COD_ZONA")) %>%
rename(NOME_ZONA_DESTINO = NOME_ZONA) %>%
filter(NOME_ZONA_ORIGEM == "Luz") %>%
select(NOME_ZONA_DESTINO, QTD) %>%
arrange(desc(QTD))## # Source: lazy query [?? x 2]
## # Database: sqlite 3.22.0
## # [/home/sillas/R/Projetos/pesquisa_origem_destino/data/DB_ORIGEM_DESTINO_SP]
## # Ordered by: desc(QTD)
## NOME_ZONA_DESTINO QTD
## <chr> <dbl>
## 1 Luz 18425.
## 2 Bom Retiro 3702.
## 3 Parque Dom Pedro 2752.
## 4 Santa Ifigênia 2550.
## 5 Santa Cecília 1945.
## 6 Ponte Pequena 1712.
## 7 Saúde 1392.
## 8 Vila Formosa 1368.
## 9 Pari 1304.
## 10 Ermelino Matarazzo 1261.
## # … with more rowsE Python?
Também é bem fácil importar um arquivo SQLite no Python combinando os módulos sqlite3 e pandas.
import sqlite3
import pandas as pd
x = '/home/sillas/R/Projetos/pesquisa_origem_destino/data/DB_ORIGEM_DESTINO_SP'
con = sqlite3.connect(x)
# importar tabela como um dataframe no pandas
tb = pd.read_sql_query('SELECT * FROM dicionario_das_variaveis_da_tabela_dados_gerais', con)